

LLM Evaluation Frameworks 2025–2026 | MLAI Digital

Prerna Sahni
LLM
1. Hook: The Evaluation Illusion
LLM evaluation frameworks have long promised clarity clean scores, benchmark rankings, and confident deployment decisions. But here’s the uncomfortable truth: your model might score 90% on paper yet still frustrate real users. This gap between measured performance and experienced performance is where most teams struggle today.
At MLAI Digital, we’ve seen these firsthand organizations investing heavily in model optimization, only to discover that real-world applications behave unpredictably. The reason? Evaluation is no longer just about scoring outputs. It’s about understanding systems, users, and outcomes.
Between 2025 and 2026, what has changed is fundamental. Evaluation has shifted from mere measurement to a system-oriented approach.
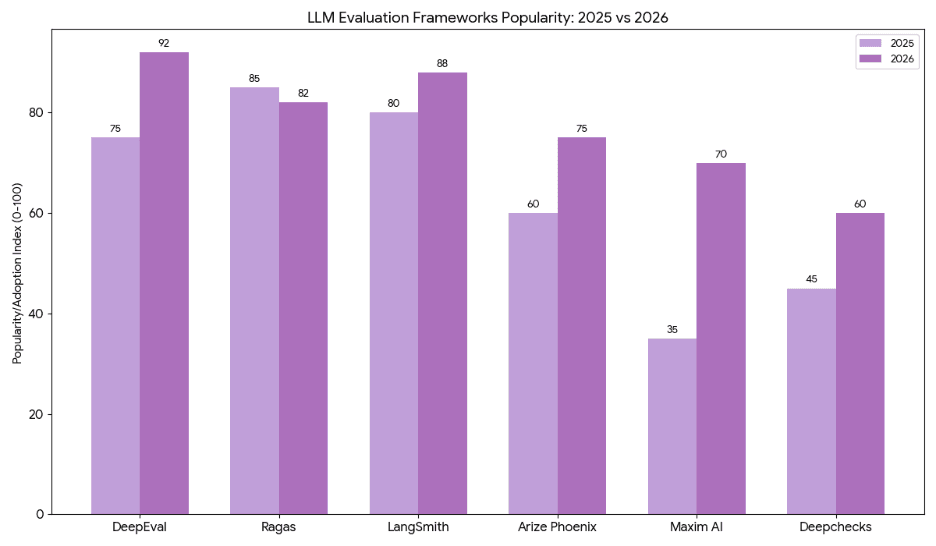
2. Quick Recap: How We Evaluated LLMs in 2025
2.1 Benchmark-Centric World
By 2025, the ecosystem revolved around benchmarks like:
MMLU
HumanEval
GSM8K
These datasets became the gold standard. If your model ranked high, it was considered “good.” Decision-making often relied heavily on leaderboard positions rather than real-world testing.
However, these benchmarks mostly measured narrow capabilities like reasoning, coding, or knowledge recall in controlled environments. They rarely captured how models behave with messy, ambiguous, or incomplete real-world inputs, something users deal with every day.
2.2 Static Evaluation Pipelines
Evaluation pipelines were mostly static:
Run tests once
Validate performance
Deploy
There was little emphasis on continuous monitoring or post-deployment learning. Once a model passed evaluation, it was assumed to be ready.
In reality, model behavior can drift over time due to changes in user queries, integrations, or updates. Static pipelines failed to catch these shifts, leading to performance degradation in production without teams even realizing it.
2.3 Human Evaluation (But Limited)
Human evaluation existed, but it was:
Expensive
Slow
Narrow in scope
Usually, it was solely used in fine-tuning or validation, not in the running process.
Due to budget and time constraints, humans only reviewed small samples. Due to this, in most edge cases, nuanced failures of tone, and subtle hallucinations or context misunderstanding were missed.
2.4 Key Limitation Summary
The 2025 approach had critical flaws:
Overfitting to benchmarks
Weak correlation with real-world performance
No feedback loops
Lack of adaptability
Teams ended up optimizing the score rather than the outcome, creating systems that looked amazing during the demo, but failed in production. This gap drove the development of LLM evaluation frameworks that are more interactive and concentrated on the user.
3. What Broke: Why 2025 Methods Stopped Working
3.1 Rise of Real-World Complexity
Applications became more sophisticated:
Multi-turn conversations
AI agents performing tasks
Long-context reasoning
Tool integrations
Suddenly, single-turn benchmark testing wasn’t enough.
In real-world scenarios, users don’t ask perfect one-line questions they interact with, clarify, change context, and expect continuity. Models now need to remember, adapt, and act, which traditional evaluations were never designed to measure.
3.2 Distribution Shift Problem
The biggest issue? Benchmarks didn’t reflect production data.
Things that worked in controlled situations didn’t work in the real world where the inputs were messy, ambiguous, and unpredictable.
For example, users might provide incomplete information, mix languages, or ask vague questions. These variations create a gap between test performance and real usage; something earlier LLM evaluation frameworks failed to capture effectively.
3.3 “Looks Good on Paper” Failure Cases
Teams began noticing patterns:
High-scoring models hallucinating in critical applications
Chatbots giving fluent but incorrect responses
Systems failing silently in edge cases
This raised a big red flag: the existing framework for LLM evaluations measure intelligence, not usefulness.
In practice, a response that sounds right but is factually wrong can be more harmful than a obvious failure. Trustworthiness, reliability, and real-world impact have taken importance over accuracy scores in contemporary evaluation.
4. 2026 Shift: From Model Evaluation → System Evaluation
4.1 LLMs Are Now Components, Not Products
In 2026, LLMs are rarely standalone. They are embedded within:
AI agents
Business workflows
Customer-facing applications
This shift means evaluating just the model is no longer sufficient.
Today, the model is only one part of a larger system that includes prompts, APIs, tools, and user interfaces. Even a highly capable model can fail if the surrounding system like retrieval, memory, or orchestration, is poorly designed.
4.2 Evaluation Unit Has Changed
Before: Model output quality
Now: End-to-end task success
The question is no longer “Is the answer correct?”
It’s “Did the system solve the user’s problem?”
For example, in a customer support bot, success isn’t just giving the right answer it’s resolving the issue quickly, clearly, and without requiring repeated user effort. This shift is central to modern LLM evaluation frameworks.
4.3 New Evaluation Questions
Modern LLM evaluation frameworks focus on:
Did the user achieve their goal?
Was the response trustworthy?
Did the system recover from errors?
Was the interaction smooth and efficient?
These questions go beyond technical accuracy and focus on real user experience. They help teams evaluate not just what the model says, but how effectively the entire system performs in practical scenarios.
The latest LLM evaluation benchmark hits a historic milestone as success counts in outcomes not output anymore.
5. Modern Evaluation Stack (2026)
5.1 Offline Evaluation (Still Exists, But Evolved)
Offline evaluation hasn’t disappeared; it has matured.
Now it includes:
Synthetic datasets
Scenario-based testing
Adversarial prompts
The focus has shifted from accuracy to coverage. Teams now ask:
“Have we tested enough real-world scenarios?”
Teams now mimic live user experiences. These can range from leaving queries half-finished, providing complex instructions or triggering failures. The system can be intentionally “broken” through the use of adversarial prompts to find an error before it is found by users. Offline evaluation is conducted to ensure certain benefits rather than validating reality.
5.2 Online Evaluation (Now Critical)
This is where things get interesting.
Modern systems rely heavily on:
A/B testing LLM behavior
Real-time feedback loops
Behavioral signals such as:
User drop-offs
Re-prompts
Edits
This is central to how to evaluate large language models in real-world applications.
Unlike offline inspecting, online experimenting is a true reflection of user utilization behavior. When users have to rephrase their questions repeatedly, it usually means that the system doesn’t understand the intent. Often these subtle signals tell us things far beyond the traditional metrics, making online evaluation an important aspect of modern LLM evaluation frameworks.
5.3 LLM-as-a-Judge (But with Guardrails)
Using LLMs to evaluate other LLMs has become popular.
Pros:
Scalable
Fast
Cons:
Bias
Inconsistency
To address this, modern LLM evaluation frameworks use:
Calibration techniques
Ensemble judging (multiple evaluators)
Ground-truth anchoring
Using a single LLM judge to evaluate a LLM in practice can give unreliable results. This is the reason teams combine various evaluation models and evaluate outputs with known correct answers. Implementing this two-step process gives a cushion to the automated evaluation results.
5.4 Human-in-the-Loop (Reimagined)
Human evaluation is no longer just labeling data.
It now includes:
Auditing edge cases
Aligning outputs with brand voice
Validating critical decisions
Humans act as quality controllers, not just annotators.
In industries such as healthcare and finance, human reviewers are employed to ensure responses are correct, safe, compliant and appropriate for the context. This creates a judgment which still remains eluding on the part of automation that is vital for a human in the evaluation pipeline.
5.5 Agent & Tooling Evaluation
A completely new dimension in 2026:
Tool selection accuracy
Execution correctness
Multi-step reasoning validation
This is one of the biggest additions in LLM evaluation metrics 2026.
As LLM-powered agents interact with APIs, databases, and external tools, evaluation must go beyond text output. It now includes verifying whether the right tool was chosen, whether actions were executed correctly, and whether the system followed logical steps to complete a task. This reflects the broader shift in LLM evaluation frameworks from language generation to real-world task execution.
6. Key Metrics That Actually Matter Now
Let's examine the top metrics for evaluating LLM systems in 2026. Unlike conventional approaches that overemphasize accuracy scores, these metrics are instead meant to take into account performance in the real world, user experience, and impact on business. At the center of modern LLM evaluation frameworks lies in this shift.
6.1 Task Success Rate
The most important metric today:
Did the user accomplish their goal?
Everything else is secondary.
This metric connects AI performance directly to outcomes. For an e-commerce assistant, success happens when a user makes the purchase and doesn’t drop out. When teams concentrate on outcomes rather than outputs, they will be able to tell if the system is useful.
6.2 Reliability / Consistency
Consistency matters more than brilliance.
Same input → similar output quality
Reduced randomness in critical systems
Users feel frustrated when there’s unpredictability; their trust also diminishes. When a system gives different responses to the same question, users lose confidence quickly. That’s why modern LLM evaluation frameworks prioritize stable and repeatable performance over occasional “perfect” responses.
6.3 Hallucination Rate (Context-Aware)
Especially important in RAG systems:
Is the output grounded in data?
Does it fabricate information?
Living with hallucinations is now evaluated with context. For example, if the system that was supposed to respond based on the retrieved documents introduces unsupported facts, it is a serious failure. As hallucinations may mislead users, their reduction is paramount for reliable applications.
6.4 Latency + Cost Efficiency
Performance is now multi-dimensional:
Fast responses
Cost-effective operations
In chat-based applications, users expect almost instant feedback. Businesses must manage infrastructure costs at the same time. A system that is accurate, but slow (or expensive) is unlikely to be viable at scale; hence, latency and cost have become important parts of the evaluation metrics of LLMs 2026.
6.5 User Satisfaction Signals
Real-world signals include:
Thumbs up/down
Retention rates
Trust indicators
These signals capture the user’s actual experience, which no benchmark can fully measure. For example, frequent negative feedback or users abandoning conversations midway can highlight deeper issues in usability or response quality. This makes user satisfaction one of the most honest and valuable indicators in LLM evaluation frameworks.
When used together, these metrics convey the evolution of LLM evaluation from measuring isolated model performance to effectively delivering value in the real world.
7. Evaluation in RAG Systems
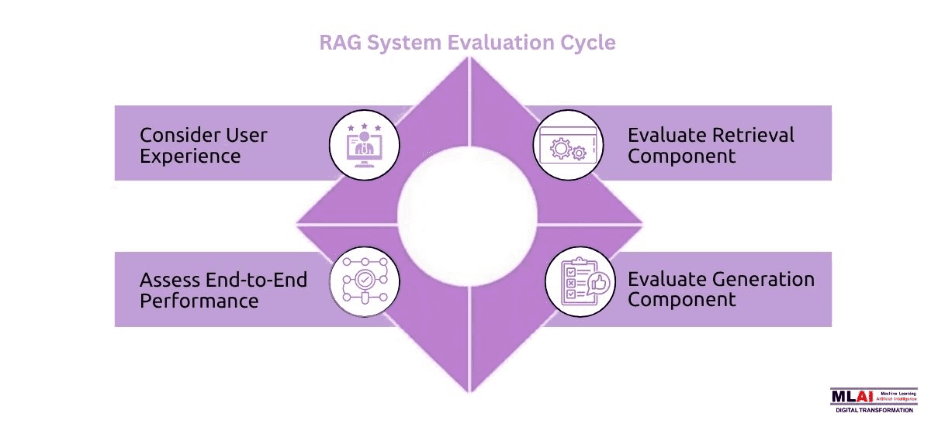
RAG systems have gained immense importance in modern-day applications of AI, especially where accuracy and relevance to the real world matter. Nonetheless, we do need to evaluate them a little differently than LLMs. It is the advanced LLM evaluation framework that matters here.
7.1 Retrieval Quality
The first step:
Are you retrieving the right documents?
Poor retrieval = poor output.
No matter how sophisticated a language model is, it cannot generate a correct answer if the context does not fit. Evaluating retrieval quality is crucial, which means checking whether the system is getting the most relevant, recent, and useful information for this query. Metrics such as precision, recall, and ranking relevance are typically used to evaluate this layer.
7.2 Groundedness
Is the response actually supported by retrieved data?
This is critical for reducing hallucinations.
Groundedness means the model’s reply is based on information retrieved from within context as opposed to the model’s own assumptions. Essentially, this involves checking whether the answer’s every claim has a source that is trustworthy. A good groundedness is essential for trust to build, e.g. in enterprise search, knowledge assistants.
7.3 Faithfulness vs Fluency
A key distinction:
Fluency: Sounds good
Faithfulness: Is correct
In 2026, correctness always wins.
A lot of LLMs are very capable of generating fluent and human-like text but yet, they do not guarantee accuracy. A reply can be quite convincing while being wrong or misleading. Modern evaluation frameworks have moved beyond traditional fluency metrics towards a focus on faithfulness, ensuring that LLMs produce text that is not only fluent but also faithful to the source of data.
Together, these dimensions demonstrate how the evolution of LLM evaluation expanded from mere content quality to assessing information reliability and real-world system accuracy.
8. Common Mistakes Teams Still Make in 2026
Despite advancements, many teams still struggle.
Common mistakes include:
Relying only on benchmarks
Ignoring real user behavior
Over-trusting LLM judges
Not testing edge cases
Skipping continuous evaluation
These mistakes highlight gaps in adopting modern LLM evaluation frameworks.
9. Practical Framework: How to Evaluate Your LLM Today
Use this simple but actionable strategy immediately whenever you feel stressed. Moving beyond theory and implementing LLM evaluation frameworks in real-world systems is the objective.
Step 1: Define Real User Tasks
Focus on what users actually want to achieve.
Instead of evaluating generic prompts, map out real use cases like resolving a customer's query, generating a report, or retrieving specific information. By doing so, the assessment reflects true user intent and not an artificial test. Your evaluation results will be more valuable the more similar your tasks are to actual use.
Step 2: Build Scenario-Based Test Sets
Simulate real-world situations, not just ideal inputs.
Make sure to include messy, incomplete, ambiguous queries that users might include. Try testing out vague questions, follow-ups, or conflicting instructions in your system. As the world is very adaptive and dynamic, things or patterns that work during training of the model may not work in the live production.
Step 3: Combine Evaluation Methods
Use a hybrid approach:
Offline evaluation
Online signals
LLM judges
Human review
An individual process is not sufficient on its own. You can confirm your scenarios offline before you deploy. Online signals tell you how users really use your system. The scalability comes from large language model judges, with human review for quality and alignment. When all of these techniques are employed together, you get a more balanced and dependable evaluation process.
Step 4: Track System-Level Metrics
Shift from output quality → outcome success.
Rather than concentrating solely on the accuracy of the solution, evaluate whether the system addresses the issue. Monitor task completion speeds, how users feel, and error recovery. With this, your evaluation pops in accordance with business goals and user expectations, a key shift in LLM evaluation metrics 2026.
Step 5: Continuously Iterate
Evaluation is no longer a one-time step; it’s a loop.
As users change their behaviors, your system must also change. Always gather feedback, revise the test scenarios, and improve your assessment. Such a cycle ensures that the model does not lose its relevance over time and that it takes place in a true manner.
Modern LLM evaluation frameworks 2025 vs 2026 are structured based on this approach, which ensures continuous improvement, real-world impact, and quantifiable success.
10. Tools & Ecosystem
LLM evaluation frameworks are becoming increasingly important in production systems and the ecosystem is growing quickly. Rather than choosing a single solution, teams are now combining different tools to construct a dynamic stack that easily scales evaluation.
Open-Source Evaluation Tools
With the help of open-source tools, teams find it easier to get started with evaluation without a large investment upfront.
These tools often come equipped with out-of-the-box benchmarks, testing flows, and customizable evaluation processes. It allows teams to experiment, change metrics, and embed assessment in their work practices. However, these usually need more configurations and customization to fit a specific business use case.
Observability Platforms
Observability platforms help teams monitor how LLM systems perform in production environments.
These facilitate real-time insights into model behavior, output quality, response latency, and response failure. For instance, teams can identify drop-off points, error occurrences, or queries that repeatedly generate unsatisfactory outcomes. It is important to ensure the systems are working correctly and efficiently.
Feedback Collection Systems
Feedback systems capture direct and indirect input from users.
The ratings (thumbs up/down) are asked explicitly, and implicit signals include repeated queries or stopping the current session. By gathering and analyzing feedback from users, teams understand the satisfaction level and where to improve, something metrics won’t find.
Instead of a single tool, teams now build evaluation stacks that are specific to their applications. Through integration of these open-source technologies along with observability platforms and feedback systems, a more comprehensive and adaptive approach is created, one which caters to the modern evolution of LLM evaluation and supports continuous improvement.
11. Future Outlook: Where Evaluation Is Heading
The next phase of evolution for the evaluation of LLM is taking place to develop smarter and faster as well as user-centric systems. The performance evaluation methods of modern large language models are being automated and more versatile.
Self-Improving Evaluation Loops
Evaluation systems are becoming more autonomous.
Future systems will learn from user interaction as well as feedback from failures, instead of having a manual update. Evaluation of pipelines will automatically reveal new weaknesses, generate new test cases, and improve the pipeline over time. Essentially, this creates a feedback loop whereby the system helps evaluate itself.
Real-Time Monitoring Systems
Evaluation is shifting from periodic checks to continuous, real-time monitoring.
As a user interacts with the system, teams will track performance on the spot. Failure detection is critical, so we define thresholds for inputs and outputs along the pipeline. If something breaks, e.g., spikes in hallucinations or drops in task success, we will detect and intervene immediately. It ensures a stable and reliable business in an evolving environment.
Personalized Evaluation (User-Specific Feedback)
Not all users are the same, and future evaluation systems will reflect that.
The evaluation will not use the same metrics for all users; instead, it will vary based on user behavior, preferences, and expectations. For instance, the meaning of a “good response” might differ for a developer and a non-developer. The use of personalized evaluations helps tailor systems to provide targeted experiences.
Alignment-Focused Metrics
Future metrics will go beyond performance and focus more on alignment with human values and intent.
This includes evaluating whether responses are safe, ethical, unbiased, and aligned with brand or organizational guidelines. As LLMs are used in more sensitive domains, alignment will become just as important as accuracy in LLM evaluation metrics 2026 and beyond.
Overall, evaluation will become more adaptive, automated, and user centric. The future of LLM evaluation frameworks lies in systems that not only measure performance but actively contribute to improving it in real time.
12. The New Reality
Let’s simplify the shift:
2025: “How smart is the model?”
2026: “Does the system actually work for users?”
The best-performing systems today are not the ones topping leaderboards; they’re the ones solving real problems consistently.
Modern LLM evaluation frameworks reflect this shift. They prioritise outcomes, reliability, and user experience over abstract scores.
Summary
From 2025 to 2026, LLM evaluation frameworks have advanced from benchmark-based model evaluation to system-level evaluation. Traditional metrics did not reflect real-world performance, resulting in unreliable user experiences. The task success, reliability, groundedness and user satisfaction were evaluated in 2026. New methods merge offline experiments, online responses, judge algorithms, and human review. As the evaluation of agents and RAG systems includes tool usage and retrieval of quality, agents and RAGs are gaining attraction. The bottom line is that successful LLM systems are not determined by scores, but by their ability to consistently solve users’ problems in transacting settings.
1. Hook: The Evaluation Illusion
LLM evaluation frameworks have long promised clarity clean scores, benchmark rankings, and confident deployment decisions. But here’s the uncomfortable truth: your model might score 90% on paper yet still frustrate real users. This gap between measured performance and experienced performance is where most teams struggle today.
At MLAI Digital, we’ve seen these firsthand organizations investing heavily in model optimization, only to discover that real-world applications behave unpredictably. The reason? Evaluation is no longer just about scoring outputs. It’s about understanding systems, users, and outcomes.
Between 2025 and 2026, what has changed is fundamental. Evaluation has shifted from mere measurement to a system-oriented approach.
2. Quick Recap: How We Evaluated LLMs in 2025
2.1 Benchmark-Centric World
By 2025, the ecosystem revolved around benchmarks like:
MMLU
HumanEval
GSM8K
These datasets became the gold standard. If your model ranked high, it was considered “good.” Decision-making often relied heavily on leaderboard positions rather than real-world testing.
However, these benchmarks mostly measured narrow capabilities like reasoning, coding, or knowledge recall in controlled environments. They rarely captured how models behave with messy, ambiguous, or incomplete real-world inputs, something users deal with every day.
2.2 Static Evaluation Pipelines
Evaluation pipelines were mostly static:
Run tests once
Validate performance
Deploy
There was little emphasis on continuous monitoring or post-deployment learning. Once a model passed evaluation, it was assumed to be ready.
In reality, model behavior can drift over time due to changes in user queries, integrations, or updates. Static pipelines failed to catch these shifts, leading to performance degradation in production without teams even realizing it.
2.3 Human Evaluation (But Limited)
Human evaluation existed, but it was:
Expensive
Slow
Narrow in scope
Usually, it was solely used in fine-tuning or validation, not in the running process.
Due to budget and time constraints, humans only reviewed small samples. Due to this, in most edge cases, nuanced failures of tone, and subtle hallucinations or context misunderstanding were missed.
2.4 Key Limitation Summary
The 2025 approach had critical flaws:
Overfitting to benchmarks
Weak correlation with real-world performance
No feedback loops
Lack of adaptability
Teams ended up optimizing the score rather than the outcome, creating systems that looked amazing during the demo, but failed in production. This gap drove the development of LLM evaluation frameworks that are more interactive and concentrated on the user.
3. What Broke: Why 2025 Methods Stopped Working
3.1 Rise of Real-World Complexity
Applications became more sophisticated:
Multi-turn conversations
AI agents performing tasks
Long-context reasoning
Tool integrations
Suddenly, single-turn benchmark testing wasn’t enough.
In real-world scenarios, users don’t ask perfect one-line questions they interact with, clarify, change context, and expect continuity. Models now need to remember, adapt, and act, which traditional evaluations were never designed to measure.
3.2 Distribution Shift Problem
The biggest issue? Benchmarks didn’t reflect production data.
Things that worked in controlled situations didn’t work in the real world where the inputs were messy, ambiguous, and unpredictable.
For example, users might provide incomplete information, mix languages, or ask vague questions. These variations create a gap between test performance and real usage; something earlier LLM evaluation frameworks failed to capture effectively.
3.3 “Looks Good on Paper” Failure Cases
Teams began noticing patterns:
High-scoring models hallucinating in critical applications
Chatbots giving fluent but incorrect responses
Systems failing silently in edge cases
This raised a big red flag: the existing framework for LLM evaluations measure intelligence, not usefulness.
In practice, a response that sounds right but is factually wrong can be more harmful than a obvious failure. Trustworthiness, reliability, and real-world impact have taken importance over accuracy scores in contemporary evaluation.
4. 2026 Shift: From Model Evaluation → System Evaluation
4.1 LLMs Are Now Components, Not Products
In 2026, LLMs are rarely standalone. They are embedded within:
AI agents
Business workflows
Customer-facing applications
This shift means evaluating just the model is no longer sufficient.
Today, the model is only one part of a larger system that includes prompts, APIs, tools, and user interfaces. Even a highly capable model can fail if the surrounding system like retrieval, memory, or orchestration, is poorly designed.
4.2 Evaluation Unit Has Changed
Before: Model output quality
Now: End-to-end task success
The question is no longer “Is the answer correct?”
It’s “Did the system solve the user’s problem?”
For example, in a customer support bot, success isn’t just giving the right answer it’s resolving the issue quickly, clearly, and without requiring repeated user effort. This shift is central to modern LLM evaluation frameworks.
4.3 New Evaluation Questions
Modern LLM evaluation frameworks focus on:
Did the user achieve their goal?
Was the response trustworthy?
Did the system recover from errors?
Was the interaction smooth and efficient?
These questions go beyond technical accuracy and focus on real user experience. They help teams evaluate not just what the model says, but how effectively the entire system performs in practical scenarios.
The latest LLM evaluation benchmark hits a historic milestone as success counts in outcomes not output anymore.
5. Modern Evaluation Stack (2026)
5.1 Offline Evaluation (Still Exists, But Evolved)
Offline evaluation hasn’t disappeared; it has matured.
Now it includes:
Synthetic datasets
Scenario-based testing
Adversarial prompts
The focus has shifted from accuracy to coverage. Teams now ask:
“Have we tested enough real-world scenarios?”
Teams now mimic live user experiences. These can range from leaving queries half-finished, providing complex instructions or triggering failures. The system can be intentionally “broken” through the use of adversarial prompts to find an error before it is found by users. Offline evaluation is conducted to ensure certain benefits rather than validating reality.
5.2 Online Evaluation (Now Critical)
This is where things get interesting.
Modern systems rely heavily on:
A/B testing LLM behavior
Real-time feedback loops
Behavioral signals such as:
User drop-offs
Re-prompts
Edits
This is central to how to evaluate large language models in real-world applications.
Unlike offline inspecting, online experimenting is a true reflection of user utilization behavior. When users have to rephrase their questions repeatedly, it usually means that the system doesn’t understand the intent. Often these subtle signals tell us things far beyond the traditional metrics, making online evaluation an important aspect of modern LLM evaluation frameworks.
5.3 LLM-as-a-Judge (But with Guardrails)
Using LLMs to evaluate other LLMs has become popular.
Pros:
Scalable
Fast
Cons:
Bias
Inconsistency
To address this, modern LLM evaluation frameworks use:
Calibration techniques
Ensemble judging (multiple evaluators)
Ground-truth anchoring
Using a single LLM judge to evaluate a LLM in practice can give unreliable results. This is the reason teams combine various evaluation models and evaluate outputs with known correct answers. Implementing this two-step process gives a cushion to the automated evaluation results.
5.4 Human-in-the-Loop (Reimagined)
Human evaluation is no longer just labeling data.
It now includes:
Auditing edge cases
Aligning outputs with brand voice
Validating critical decisions
Humans act as quality controllers, not just annotators.
In industries such as healthcare and finance, human reviewers are employed to ensure responses are correct, safe, compliant and appropriate for the context. This creates a judgment which still remains eluding on the part of automation that is vital for a human in the evaluation pipeline.
5.5 Agent & Tooling Evaluation
A completely new dimension in 2026:
Tool selection accuracy
Execution correctness
Multi-step reasoning validation
This is one of the biggest additions in LLM evaluation metrics 2026.
As LLM-powered agents interact with APIs, databases, and external tools, evaluation must go beyond text output. It now includes verifying whether the right tool was chosen, whether actions were executed correctly, and whether the system followed logical steps to complete a task. This reflects the broader shift in LLM evaluation frameworks from language generation to real-world task execution.
6. Key Metrics That Actually Matter Now
Let's examine the top metrics for evaluating LLM systems in 2026. Unlike conventional approaches that overemphasize accuracy scores, these metrics are instead meant to take into account performance in the real world, user experience, and impact on business. At the center of modern LLM evaluation frameworks lies in this shift.
6.1 Task Success Rate
The most important metric today:
Did the user accomplish their goal?
Everything else is secondary.
This metric connects AI performance directly to outcomes. For an e-commerce assistant, success happens when a user makes the purchase and doesn’t drop out. When teams concentrate on outcomes rather than outputs, they will be able to tell if the system is useful.
6.2 Reliability / Consistency
Consistency matters more than brilliance.
Same input → similar output quality
Reduced randomness in critical systems
Users feel frustrated when there’s unpredictability; their trust also diminishes. When a system gives different responses to the same question, users lose confidence quickly. That’s why modern LLM evaluation frameworks prioritize stable and repeatable performance over occasional “perfect” responses.
6.3 Hallucination Rate (Context-Aware)
Especially important in RAG systems:
Is the output grounded in data?
Does it fabricate information?
Living with hallucinations is now evaluated with context. For example, if the system that was supposed to respond based on the retrieved documents introduces unsupported facts, it is a serious failure. As hallucinations may mislead users, their reduction is paramount for reliable applications.
6.4 Latency + Cost Efficiency
Performance is now multi-dimensional:
Fast responses
Cost-effective operations
In chat-based applications, users expect almost instant feedback. Businesses must manage infrastructure costs at the same time. A system that is accurate, but slow (or expensive) is unlikely to be viable at scale; hence, latency and cost have become important parts of the evaluation metrics of LLMs 2026.
6.5 User Satisfaction Signals
Real-world signals include:
Thumbs up/down
Retention rates
Trust indicators
These signals capture the user’s actual experience, which no benchmark can fully measure. For example, frequent negative feedback or users abandoning conversations midway can highlight deeper issues in usability or response quality. This makes user satisfaction one of the most honest and valuable indicators in LLM evaluation frameworks.
When used together, these metrics convey the evolution of LLM evaluation from measuring isolated model performance to effectively delivering value in the real world.
7. Evaluation in RAG Systems
RAG systems have gained immense importance in modern-day applications of AI, especially where accuracy and relevance to the real world matter. Nonetheless, we do need to evaluate them a little differently than LLMs. It is the advanced LLM evaluation framework that matters here.
7.1 Retrieval Quality
The first step:
Are you retrieving the right documents?
Poor retrieval = poor output.
No matter how sophisticated a language model is, it cannot generate a correct answer if the context does not fit. Evaluating retrieval quality is crucial, which means checking whether the system is getting the most relevant, recent, and useful information for this query. Metrics such as precision, recall, and ranking relevance are typically used to evaluate this layer.
7.2 Groundedness
Is the response actually supported by retrieved data?
This is critical for reducing hallucinations.
Groundedness means the model’s reply is based on information retrieved from within context as opposed to the model’s own assumptions. Essentially, this involves checking whether the answer’s every claim has a source that is trustworthy. A good groundedness is essential for trust to build, e.g. in enterprise search, knowledge assistants.
7.3 Faithfulness vs Fluency
A key distinction:
Fluency: Sounds good
Faithfulness: Is correct
In 2026, correctness always wins.
A lot of LLMs are very capable of generating fluent and human-like text but yet, they do not guarantee accuracy. A reply can be quite convincing while being wrong or misleading. Modern evaluation frameworks have moved beyond traditional fluency metrics towards a focus on faithfulness, ensuring that LLMs produce text that is not only fluent but also faithful to the source of data.
Together, these dimensions demonstrate how the evolution of LLM evaluation expanded from mere content quality to assessing information reliability and real-world system accuracy.
8. Common Mistakes Teams Still Make in 2026
Despite advancements, many teams still struggle.
Common mistakes include:
Relying only on benchmarks
Ignoring real user behavior
Over-trusting LLM judges
Not testing edge cases
Skipping continuous evaluation
These mistakes highlight gaps in adopting modern LLM evaluation frameworks.
9. Practical Framework: How to Evaluate Your LLM Today
Use this simple but actionable strategy immediately whenever you feel stressed. Moving beyond theory and implementing LLM evaluation frameworks in real-world systems is the objective.
Step 1: Define Real User Tasks
Focus on what users actually want to achieve.
Instead of evaluating generic prompts, map out real use cases like resolving a customer's query, generating a report, or retrieving specific information. By doing so, the assessment reflects true user intent and not an artificial test. Your evaluation results will be more valuable the more similar your tasks are to actual use.
Step 2: Build Scenario-Based Test Sets
Simulate real-world situations, not just ideal inputs.
Make sure to include messy, incomplete, ambiguous queries that users might include. Try testing out vague questions, follow-ups, or conflicting instructions in your system. As the world is very adaptive and dynamic, things or patterns that work during training of the model may not work in the live production.
Step 3: Combine Evaluation Methods
Use a hybrid approach:
Offline evaluation
Online signals
LLM judges
Human review
An individual process is not sufficient on its own. You can confirm your scenarios offline before you deploy. Online signals tell you how users really use your system. The scalability comes from large language model judges, with human review for quality and alignment. When all of these techniques are employed together, you get a more balanced and dependable evaluation process.
Step 4: Track System-Level Metrics
Shift from output quality → outcome success.
Rather than concentrating solely on the accuracy of the solution, evaluate whether the system addresses the issue. Monitor task completion speeds, how users feel, and error recovery. With this, your evaluation pops in accordance with business goals and user expectations, a key shift in LLM evaluation metrics 2026.
Step 5: Continuously Iterate
Evaluation is no longer a one-time step; it’s a loop.
As users change their behaviors, your system must also change. Always gather feedback, revise the test scenarios, and improve your assessment. Such a cycle ensures that the model does not lose its relevance over time and that it takes place in a true manner.
Modern LLM evaluation frameworks 2025 vs 2026 are structured based on this approach, which ensures continuous improvement, real-world impact, and quantifiable success.
10. Tools & Ecosystem
LLM evaluation frameworks are becoming increasingly important in production systems and the ecosystem is growing quickly. Rather than choosing a single solution, teams are now combining different tools to construct a dynamic stack that easily scales evaluation.
Open-Source Evaluation Tools
With the help of open-source tools, teams find it easier to get started with evaluation without a large investment upfront.
These tools often come equipped with out-of-the-box benchmarks, testing flows, and customizable evaluation processes. It allows teams to experiment, change metrics, and embed assessment in their work practices. However, these usually need more configurations and customization to fit a specific business use case.
Observability Platforms
Observability platforms help teams monitor how LLM systems perform in production environments.
These facilitate real-time insights into model behavior, output quality, response latency, and response failure. For instance, teams can identify drop-off points, error occurrences, or queries that repeatedly generate unsatisfactory outcomes. It is important to ensure the systems are working correctly and efficiently.
Feedback Collection Systems
Feedback systems capture direct and indirect input from users.
The ratings (thumbs up/down) are asked explicitly, and implicit signals include repeated queries or stopping the current session. By gathering and analyzing feedback from users, teams understand the satisfaction level and where to improve, something metrics won’t find.
Instead of a single tool, teams now build evaluation stacks that are specific to their applications. Through integration of these open-source technologies along with observability platforms and feedback systems, a more comprehensive and adaptive approach is created, one which caters to the modern evolution of LLM evaluation and supports continuous improvement.
11. Future Outlook: Where Evaluation Is Heading
The next phase of evolution for the evaluation of LLM is taking place to develop smarter and faster as well as user-centric systems. The performance evaluation methods of modern large language models are being automated and more versatile.
Self-Improving Evaluation Loops
Evaluation systems are becoming more autonomous.
Future systems will learn from user interaction as well as feedback from failures, instead of having a manual update. Evaluation of pipelines will automatically reveal new weaknesses, generate new test cases, and improve the pipeline over time. Essentially, this creates a feedback loop whereby the system helps evaluate itself.
Real-Time Monitoring Systems
Evaluation is shifting from periodic checks to continuous, real-time monitoring.
As a user interacts with the system, teams will track performance on the spot. Failure detection is critical, so we define thresholds for inputs and outputs along the pipeline. If something breaks, e.g., spikes in hallucinations or drops in task success, we will detect and intervene immediately. It ensures a stable and reliable business in an evolving environment.
Personalized Evaluation (User-Specific Feedback)
Not all users are the same, and future evaluation systems will reflect that.
The evaluation will not use the same metrics for all users; instead, it will vary based on user behavior, preferences, and expectations. For instance, the meaning of a “good response” might differ for a developer and a non-developer. The use of personalized evaluations helps tailor systems to provide targeted experiences.
Alignment-Focused Metrics
Future metrics will go beyond performance and focus more on alignment with human values and intent.
This includes evaluating whether responses are safe, ethical, unbiased, and aligned with brand or organizational guidelines. As LLMs are used in more sensitive domains, alignment will become just as important as accuracy in LLM evaluation metrics 2026 and beyond.
Overall, evaluation will become more adaptive, automated, and user centric. The future of LLM evaluation frameworks lies in systems that not only measure performance but actively contribute to improving it in real time.
12. The New Reality
Let’s simplify the shift:
2025: “How smart is the model?”
2026: “Does the system actually work for users?”
The best-performing systems today are not the ones topping leaderboards; they’re the ones solving real problems consistently.
Modern LLM evaluation frameworks reflect this shift. They prioritise outcomes, reliability, and user experience over abstract scores.
Summary
From 2025 to 2026, LLM evaluation frameworks have advanced from benchmark-based model evaluation to system-level evaluation. Traditional metrics did not reflect real-world performance, resulting in unreliable user experiences. The task success, reliability, groundedness and user satisfaction were evaluated in 2026. New methods merge offline experiments, online responses, judge algorithms, and human review. As the evaluation of agents and RAG systems includes tool usage and retrieval of quality, agents and RAGs are gaining attraction. The bottom line is that successful LLM systems are not determined by scores, but by their ability to consistently solve users’ problems in transacting settings.
Related Blogs
Be the first to read our articles.