

The Ultimate Guide to LLM-as-a-Judge in 2026

Prerna Sahni
LLM
If you've ever wondered whether your AI model is actually doing a good job or just confidently sounding like it is, you're not alone. The rise of LLM-as-a-Judge has changed the entire conversation around AI evaluation. No longer are teams stuck waiting on slow, expensive human reviews or relying on rigid rule-based scripts that miss the nuance of real-world responses. Today, a well-configured judge model can evaluate thousands of outputs in minutes, flag hallucinations, score faithfulness, and even reason why a response fell short. This guide is your comprehensive roadmap to understanding, implementing, and trusting LLM-based evaluation systems in 2026 - from the ground up.
1. What Is LLM-as-a-Judge?
1.1 Definition of LLM-as-a-Judge
At its core, LLM as a Judge refers to using a large language model - typically a powerful, instruction-tuned one - to evaluate the output of another AI model. Think of it as hiring a senior editor to proofread the work of a junior writer, except both are AI. The judge model receives a prompt, the original AI's response, and optionally a reference answer or rubric. It then returns a score, a verdict, or a detailed critique. The concept sounds almost recursive, but it works surprisingly well when designed thoughtfully. The judge doesn't just mechanically check facts - it reasons, weighs context, and mirrors the kind of holistic judgment a human evaluator would apply.
1.2 Why AI Systems Need Automated Evaluation
Think about the scale at which modern AI applications operate. A customer support bot might handle 50,000 conversations a day. A RAG-based knowledge assistant might answer thousands of queries from employees every hour. Manually reviewing even, a fraction of those outputs would require entire departments of human annotators - and they'd inevitably miss things, get tired, or apply standards inconsistently. Automated LLM evaluation solves this problem by providing a scalable, consistent, and programmable layer of AI quality assurance that never sleeps, never gets fatigued, and can apply the same rubric to the millionth response as it did to the first.
1.3 How LLM-as-a-Judge Differs from Traditional Evaluation Methods
Traditional LLM benchmarking relied on fixed datasets and exact match scoring. If the model said 'Paris' and the right answer was 'Paris,' it passed. If it said 'The capital of France is Paris' - it might fail, even though it was correct. That brittleness is what LLM-based evaluation overcomes. Instead of rigid string matching, judge models understand context, paraphrase equivalence, and the spirit of an answer. They can evaluate open-ended, generative outputs that no rule-based system could reliably assess. The shift is from checking answers to understanding them.
2. Why LLM-as-a-Judge Has Become Essential in 2026
2.1 Rapid Growth of AI Applications
2026 is not 2022. AI is no longer a pilot project or an innovation lab experiment. It's embedded in hospitals, law firms, banks, e-commerce platforms, and government services. Every one of those deployments generates outputs that need to be reliable. The volume of AI-generated content has exploded to a point where human oversight alone is simply not operationally viable. This explosion has made AI evaluation frameworks not just a best practice - they're a business necessity.
2.2 Limitations of Human Evaluation
Human evaluators are gold standard in many ways - they bring genuine understanding, cultural sensitivity, and domain expertise. But they're also slow, expensive, inconsistent across annotators, and prone to bias and fatigue. Two evaluators reviewing the same response can give wildly different scores depending on their background, mood, or interpretation of the rubric. LLM-as-a-Judge doesn't replace human judgment; it standardises and scales it, reserving human review for the edge cases and high-stakes outputs that truly need it.
2.3 Need for Scalable AI Quality Assurance
AI quality assurance in 2026 looks nothing like software QA from a decade ago. You can't write test cases for every possible user's query. You can't anticipate every hallucination or off-topic drift. What you can do is deploy a continuous evaluation pipeline that monitors outputs in near real-time, flags anomalies, tracks metric trends, and alerts teams before small problems become PR disasters. That's precisely what well-built LLM evaluation systems deliver - a living, breathing quality gate that evolves alongside your model.
2.4 Enterprise Adoption of Automated Evaluation
Enterprises aren't just experimenting anymore; they're standardizing. Major tech companies, consulting firms, and regulated industries have begun treating LLM evaluation metrics as part of their model of governance and compliance frameworks. In regulated sectors like healthcare and finance, demonstrating that your AI outputs are continuously monitored and evaluated is quickly becoming a compliance expectation, not just a technical nicety.
3. How LLM-as-a-Judge Works
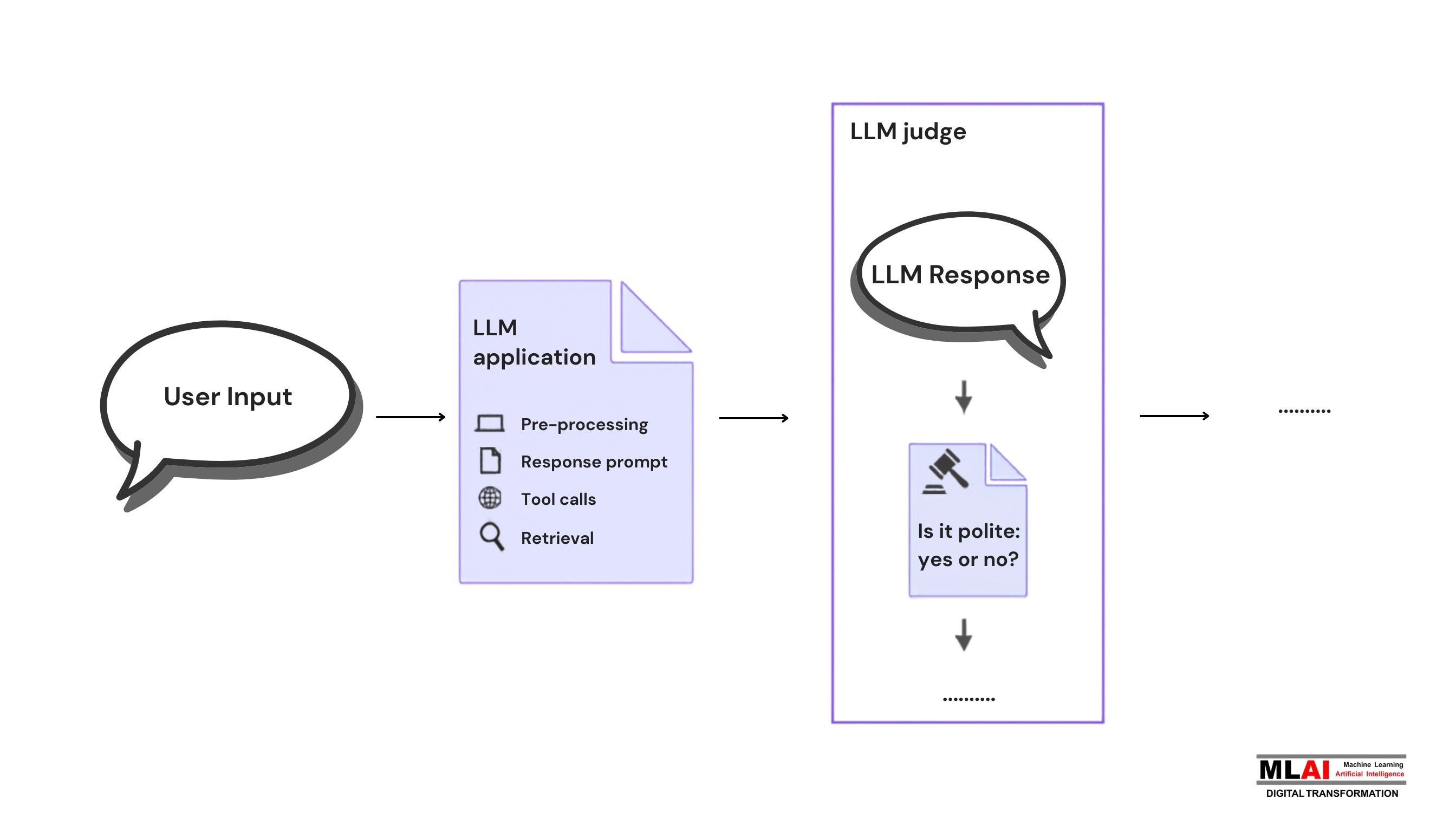
3.1 Step 1: User Query and Model Response
The process starts by capturing what actually happened in your application. A user submits a query, and the target model (the one being evaluated) generates a response. Both the query and the response are logged and passed downstream to the evaluation pipeline. This sounds simple, but getting this instrumentation right - capturing context, session state, retrieved documents, tool outputs - is foundational to everything that follows.
3.2 Step 2: Creating Evaluation Prompts
Next, the evaluation prompt is assembled. This is where real engineering happens. The prompt typically includes: the original user query, the model's response, any reference answer or ground truth, the retrieved context (in RAG scenarios), and a detailed rubric explaining what the judge should evaluate and how. The quality of this prompt directly determines the quality of your evaluation. Vague prompts produce vague judgments. Specific, well-structured prompts produce actionable insights.
3.3 Step 3: Scoring and Reasoning
The judge model then processes the evaluation prompt and generates both a score and a chain-of-thought explanation. The reasoning component is often more valuable than the score itself - it tells you not just that a response scored 3 out of 5, but why. Was the answer factually incorrect? Did it miss the user's intent? Was it technically accurate but unhelpfully verbose? This transparency is what makes LLM-based evaluation genuinely useful for improving models, not just measuring them.
3.4 Step 4: Generating Evaluation Metrics
Finally, scores and reasoning are aggregated into structured metrics. These might be stored in a database, surfaced in a monitoring dashboard, sent as alerts, or fed back into model training pipelines. The output isn't just a number - it's a dataset of diagnostic information that engineering and product teams can act on. Done well, this step closes the loop between evaluation and improvement.
4. Types of LLM-as-a-Judge Evaluation Methods
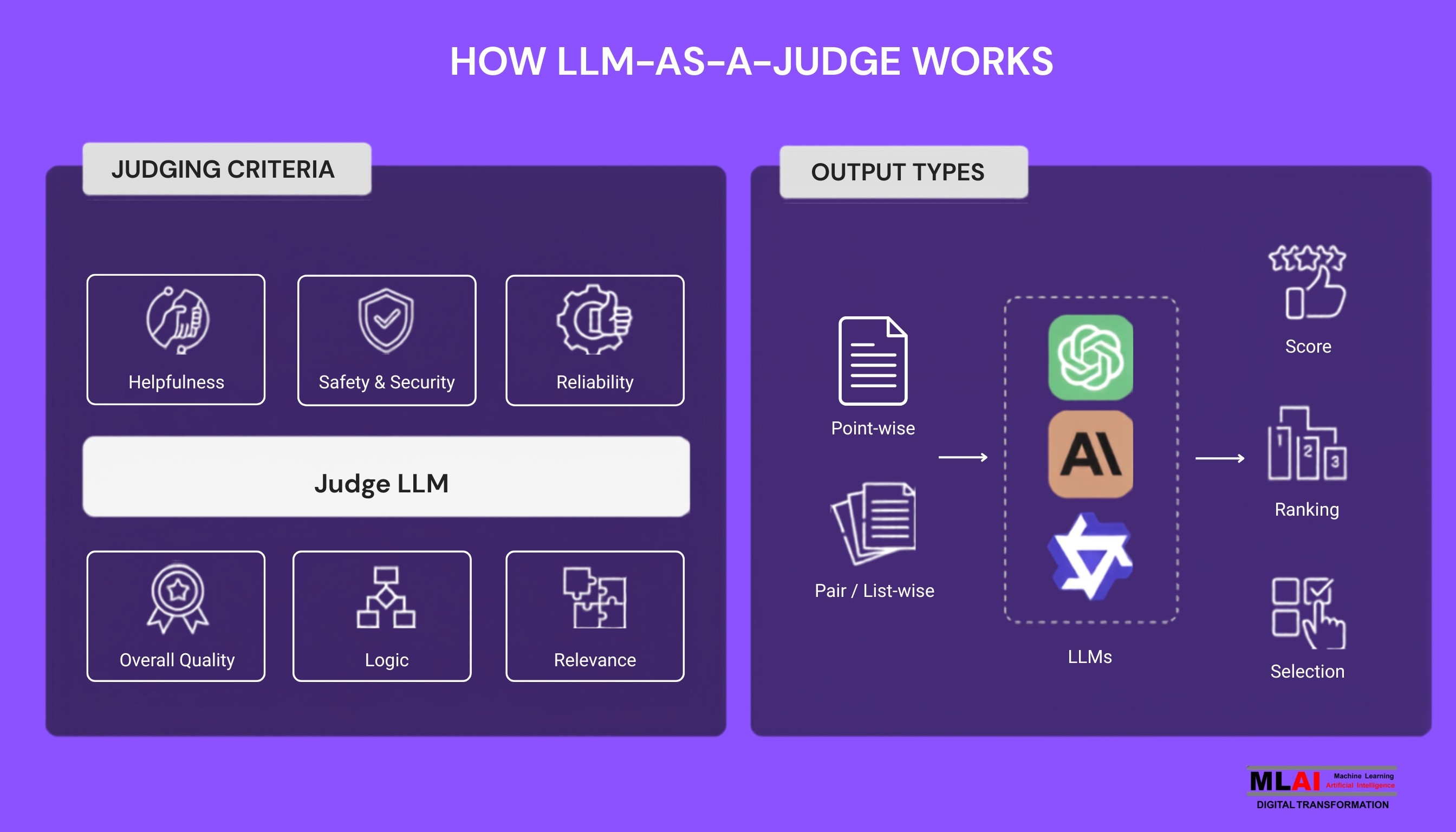
4.1 Pointwise Evaluation
Pointwise evaluation scores a single response in isolation, typically on a numerical scale (e.g., 1–5) or a categorical label (e.g., Pass/Fail). It's the simplest form and works well for high-volume, automated pipelines where you need fast, independent assessments. The downside is that scores can lack calibration - a 4/5 from one judge prompt might mean something different from another. It's best used when you have a well-defined rubric and consistent prompt design.
4.2 Pairwise Evaluation
Pairwise evaluation presents the judge with two responses to the same query and asks which is better. This mirrors how humans naturally make comparative judgments and tend to produce more reliable results than absolute scoring. It's particularly powerful during model comparison - A/B testing different model versions, prompts, or fine-tunes. The tradeoff is scale: comparing every pair across thousands of examples gets computationally expensive fast.
4.3 Listwise Evaluation
Listwise evaluation ranks multiple responses simultaneously. Instead of binary comparisons or isolated scores, the judge orders a set of responses from best to worst. This is valuable when you're evaluating retrieval systems, comparing multiple model candidates, or building preference datasets for RLHF. It's more cognitively demanding for the judge model, so prompt design matters even more here.
4.4 Rubric-Based Evaluation
Rubric-based evaluation provides the judge with a detailed, multi-dimensional scoring guide, think of it like an academic grading rubric. Each dimension (accuracy, completeness, tone, safety) gets its own criteria and weight. This is the most structured form of evaluation and produces the richest diagnostic data. It requires more upfront work to design the rubric, but it pays dividends in consistency, interpretability, and alignment with domain-specific requirements.
5. Key Evaluation Metrics Used in LLM-as-a-Judge
A robust AI evaluation framework doesn't rely on a single score. It measures across a spectrum of dimensions, each revealing a different facet of output quality. Here's what matters most:
5.1 Correctness
Does the response contain factually accurate information? Correctness is the bedrock metric; without it, everything else is polished noise. This is often evaluated against a ground truth or by the judge's own knowledge, and it's where hallucination detection plays a central role.
5.2 Relevance
Did the model actually answer what was asked? Relevance measures how well the response addresses the user's intent, not just the surface-level keywords. A technically accurate response that misses the user's actual question is still a failure.
5.3 Completeness
Was everything that needed to be said, said? Completeness catches responses that are technically correct but frustratingly partial - the kind that answer half the question and leave users searching for more.
5.4 Faithfulness Evaluation
Faithfulness evaluation is especially critical in RAG systems. It checks whether the model's claims are grounded in the retrieved source documents, rather than fabricated from prior knowledge. A model that confidently invents supporting evidence it wasn't given is a faithfulness failure - and in high-stakes domains, a serious liability.
5.5 Hallucination Detection
Hallucination detection is one of the most sought-after capabilities in any LLM evaluation metrics suite. It specifically identifies when the model states something as fact that isn't grounded in its context or training data. Modern judge models are increasingly good at catching these - but they still require thoughtful prompt design and domain-specific validation to be truly reliable.
5.6 Safety and Toxicity
Safety evaluation checks for harmful, toxic, biased, or policy-violating content. In consumer-facing applications, this is non-negotiable. Judge models can flag unsafe outputs faster and more consistently than human moderators, especially at scale.
6. LLM-as-a-Judge for RAG Evaluation
6.1 Why RAG Systems Need Specialized Evaluation
RAG evaluation is fundamentally different from evaluating a standalone language model. When you add a retrieval layer, you introduce a whole new category of failure modes. The retrieved chunks might be irrelevant. The model might ignore them and hallucinate anyway. Or the model might faithfully parrot incorrect information from a flawed document. Each of these requires a distinct evaluation lens and standard benchmarks don't capture them.
6.2 Context Relevance Evaluation
Context relevance asks: did the retrieval system surface documents that actually help answer the user's question? A high retrieval score with irrelevant chunks wastes tokens, confuses the model, and degrades output quality. Judge models can assess how well retrieved content maps to the user's intent - something keyword-based retrieval metrics completely miss.
6.3 Faithfulness Evaluation in RAG
In RAG contexts, faithfulness evaluation specifically checks whether each claim in the model's response can be traced back to the retrieved documents. If the model states something not found in the retrieved chunks, that is a faithfulness violation and potentially a serious error depending on the use case.
6.4 Hallucination Detection in RAG
RAG hallucinations are sneakier than general hallucinations. The model has real documents in front of it, so it feels more authoritative - but it may still extrapolate, blend information incorrectly, or confidently state things do not present in the context. Dedicated hallucination detection prompts that compare the response line-by-line against the retrieved context are the gold standard here.
7. LLM-as-a-Judge for AI Agent Evaluation
7.1 Challenges of Evaluating AI Agents
AI agent evaluation is arguably the hardest problem in the entire evaluation space right now. Unlike a single-turn Q&A, agents take sequences of actions, call tools, plan multi-step tasks, and operate over extended time horizons. Evaluating them requires tracking not just final outputs but intermediate reasoning, tool selection decisions, error recovery behaviors, and goal completion. Traditional metrics simply weren't built for this.
7.2 Evaluating Tool Usage
Did the agent use the right tool, with the right parameters, at the right time? Tool usage evaluation is one of the most practical and high-value AI agent evaluation metrics. A judge model can review the tool call log and assess whether each action was necessary, appropriate, and correctly executed - catching both over-use (calling tools when unnecessary) and under-use (missing opportunities to retrieve critical data).
7.3 Evaluating Planning and Reasoning
Reasoning quality is the hardest thing to evaluate, but also the most important thing. Judge models can assess whether the agent's chain-of-thought was logical, whether it correctly identified subgoals, and whether its plan was coherent given the available information. This requires sophisticated judge prompts - but when done well, it provides insight no other evaluation method can.
7.4 Task Completion Assessment
Ultimately, did the agent accomplish what it was asked to do? Task completion assessment is the bottom-line metric for agentic systems. It requires the judge to understand the original goal, trace the execution path, and make a holistic determination about success - including partial credit for tasks that were mostly completed.
8. Popular LLM-as-a-Judge Frameworks and Tools in 2026
The ecosystem of automated LLM evaluation tools has matured significantly. Here's a practical rundown of what's worth knowing:
8.1 DeepEval
DeepEval has become one of the most developer-friendly evaluation frameworks in the ecosystem. It supports a wide range of LLM evaluation metrics out of the box - hallucination, faithfulness, answer relevancy, contextual precision - and integrates cleanly into CI/CD pipelines. Its syntax is intuitive enough for quick adoption while being flexible enough for production-grade deployments.
8.2 Ragas
Ragas was purpose-built for RAG evaluation and remains the go-to tool for teams with retrieval-augmented architectures. Its core metrics - context relevance, faithfulness evaluation, answer relevance, and context recall - map directly to the failure modes that RAG systems encounter in production. If you're building on top of a vector database and retrieval pipeline, Ragas should be in your stack.
8.3 LangSmith
LangSmith offers the most polished observability experience for LangChain-based applications. Its evaluation suite is tightly integrated with tracing, making it easy to correlate evaluation outcomes with specific execution paths. For teams already in the LangChain ecosystem, it's often the default choice.
8.4 OpenAI Evals
OpenAI's open-source evaluation framework is highly flexible and supports custom evaluation graders alongside built-in metrics. It's particularly strong for model-level benchmarking and is widely used for LLM benchmarking across research and enterprise settings.
8.5 Braintrust
Braintrust focuses on continuous evaluation and dataset management. It shines in iterative development workflows where you're rapidly tuning prompts and need to track evaluation scores across experiments over time. Its UI makes it easy to spot regressions and understand what changed between runs.
8.6 Phoenix by Arize AI
Phoenix is Arize AI's open-source observability and evaluation tool. It's particularly well-suited for production monitoring use cases - tracking quality drift over time, surfacing problematic clusters of outputs, and integrating with existing ML observability infrastructure.
9. Building an LLM-as-a-Judge System
9.1 Define Evaluation Objectives
Before writing a single line of evaluation code, get crystal clear on what you're trying to measure and why. Are you monitoring a production system for quality drift? Comparing model versions before a deployment? Auditing for compliance? Each of these objectives demands a different evaluation design. Skipping this step leads to evaluation systems that generate numbers without generating insight.
9.2 Create Evaluation Rubrics
A good rubric is half the battle. For each dimension you want to evaluate, define clearly what a 1 looks like versus a 3 versus a 5. Include examples. Specify edge cases. The more concrete your rubric, the more consistent and trustworthy your judge's outputs will be. Vague criteria produce vague scores - and vague scores produce useless metrics.
9.3 Select a Judge Model
Not all models make good judges. You generally want a model that is more capable than the one being evaluated, has strong instruction-following, and produces structured, consistent outputs. GPT-4 class models and Claude Opus are popular choices. For specialized domains, fine-tuned judge models are emerging as a best practice - trained specifically to apply consistent evaluation criteria in areas like legal, medical, or financial AI.
9.4 Design Evaluation Prompts
Your evaluation prompt is your most important engineering artifact. It should include: clear task framing, the full context (query + response + source documents), the rubric with scoring criteria, and an instruction to provide reasoning before delivering a score. Request structured output - JSON works well - to make downstream parsing reliable. Test your prompts extensively before deploying them to production.
9.5 Validate Against Human Ratings
Before trusting your judge in production, validate it. Collect a representative sample of human-labeled examples across the quality spectrum - high, medium, and low quality responses - and measure how well your judge's scores correlate with human ratings. An inter-rater agreement score (Cohen's Kappa or Spearman's rank correlation) gives you a calibrated sense of how much to trust the automated system.
10. Benefits of Using LLM-as-a-Judge
10.1 Scalability
The most obvious benefit: you can evaluate millions of outputs without linearly scaling your team. What would take 50 human annotators six months to review can be processed in hours. This makes continuous, production-scale AI quality assurance not just feasible, but practical.
10.2 Faster Feedback Loops
When you can evaluate a prompt change in minutes rather than weeks, you move faster. Development teams get signal almost immediately. Product teams can test UX variations. Fine-tuning runs can be assessed before they reach production. Faster evaluation means faster iteration - and faster iteration means better models.
10.3 Cost Reduction
Human annotation is expensive, especially for specialized domains. Automated LLM evaluation typically costs a fraction of equivalent human review, even with frontier model API costs factored in. The savings compound as you scale, and they allow smaller teams to maintain evaluation rigor that previously required enterprise-level annotation budgets.
10.4 Better Model Benchmarking
LLM benchmarking with judge models captures dimensions of quality that static benchmarks completely miss. You're not just measuring whether the model gets the right answer on a fixed test set - you're measuring how well it serves real users, in real conditions, on real queries. That's a fundamentally more meaningful evaluation.
11. Challenges and Limitations of LLM-as-a-Judge
Let's be honest, LLM-as-a-Judge is not perfect. Understanding its failure modes is essential to using it responsibly.
11.1 Position Bias
In pairwise evaluations, judge models often favor whichever response appears first in the prompt. This positional preference has nothing to do with actual quality and can significantly skew your comparison results. The fix: randomize response order across evaluation runs and average the results.
11.2 Length Bias
Longer responses tend to score higher even when they're padded with filler. Judge models can mistake verbosity for thoroughness. Counter this with explicit rubric criteria that reward conciseness and penalize unnecessary length.
11.3 Self-Preference Bias
Models tend to prefer responses that resemble their own style. If you use GPT-4 as a judge and GPT-4 as the evaluated model, you may get artificially inflated scores. Use a diverse set of judge models - ideally from different model families - to mitigate this.
11.4 Hallucinated Evaluations
Ironically, judge models can themselves hallucinate. They might cite reasons for a low score that aren't actually present in the response, or confidently flag a factual error that doesn't exist. This is why validation against human ratings is so important - it catches systematic evaluation errors before they corrupt your metrics.
12. Best Practices for Reliable LLM-as-a-Judge Evaluations
12.1 Use Structured Rubrics
Every evaluation dimension should have a clear, anchored rubric with concrete examples of what each score level looks like. Ambiguous criteria lead to inconsistent scores. Inconsistent scores lead to metrics you can't trust.
12.2 Perform Human Validation
Never deploy an evaluation system without first validating it against human judgments. Measure correlation, identify systematic biases, and tune your prompts accordingly. Human validation isn't a one-time exercise - revisit it periodically as your application and user base evolve.
12.3 Use Multiple Judge Models
Diversify your judge models. Using two or three models from different families - and averaging or reconciling their scores - reduces individual model biases and produces more robust evaluations. When judges disagree significantly, that's itself a signal worth investigating.
12.4 Monitor Evaluation Drift
Judge model behavior can drift over time as underlying models are updated. A score of 4/5 in January might mean something different in September. Track your evaluation distributions over time and set up alerts for significant shifts that might indicate model or evaluation drift.
13. Real-World Use Cases of LLM-as-a-Judge
13.1 Customer Support Chatbots
Customer support is one of the highest-stakes and highest-volume AI applications. Judge models evaluate response accuracy, tone appropriateness, policy compliance, and resolution quality - at the scale of millions of daily conversations. Teams use evaluation insights to identify knowledge gaps, retrain models, and catch regressions after product changes.
13.2 Enterprise Knowledge Assistants
Internal knowledge assistants built on RAG architectures need rigorous faithfulness evaluation to ensure they're citing the right internal documents and not mixing up policies, procedures, or data across departments. AI evaluation frameworks are central to maintaining trust in these high-stakes internal tools.
13.3 Healthcare AI Applications
In healthcare, the cost of hallucination is potentially a patient's wellbeing. Medical AI systems use specialized judge models trained on clinical knowledge to evaluate accuracy, completeness, and safety of AI-generated responses. These evaluation systems often combine automated LLM evaluation with mandatory human review for any flagged outputs.
13.4 Financial AI Systems
Financial AI applications face strict regulatory requirements around accuracy and explainability. Judge models help compliance teams monitor AI outputs for regulatory violations, factual errors, and inappropriate financial advice - providing an audit trail that regulators increasingly expect.
14. The Future of LLM-as-a-Judge
14.1 Specialized Judge Models
The next wave of innovation is domain-specific judge models. Rather than applying a general-purpose LLM to evaluate medical or legal or financial outputs, organizations will fine-tune dedicated judge models on expert-labeled datasets within their domain. These specialized judges will have deeper calibration and lower hallucination rates within their areas of expertise.
14.2 Agentic Evaluation Systems
As AI agents become more prevalent, evaluation systems will themselves become more agentic, automatically designing test cases, running evaluations, diagnosing failure patterns, and triggering retraining pipelines without human intervention. The evaluation layer is evolving from a reporting tool into an autonomous quality management system.
14.3 Real-Time AI Monitoring
Real-time evaluation - where outputs are scored within milliseconds of generation - is moving from experimental to practical. This enables live guardrails that can intercept and modify problematic responses before they reach users, turning evaluation from a retrospective audit into a proactive quality gate.
14.4 Human-AI Hybrid Evaluation
The future isn't purely automated - it's intelligently hybrid. Automated LLM evaluation handles the volume, applies consistent criteria, and surfaces edge cases. Human evaluators focus their expertise on the cases that matter most: novel failure modes, high-stakes outputs, and calibration of the evaluation system itself. This hybrid model delivers the best of both worlds: scale and nuance.
Conclusion
LLM-as-a-Judge is no longer optional; it is the backbone of reliable AI quality assurance in 2026. From RAG evaluation to AI agent evaluation, it gives teams the scale, consistency, and speed that human review simply cannot match. Applied with proper rubrics, thorough human validation, and diverse judge models, it turns evaluation from a costly bottleneck into a real competitive advantage. The organizations winning with AI today are not just building better models, they are measuring them smarter. Build with clear intention, evaluate continuously, catch failures early, and ship AI your users can trust every time.
If you've ever wondered whether your AI model is actually doing a good job or just confidently sounding like it is, you're not alone. The rise of LLM-as-a-Judge has changed the entire conversation around AI evaluation. No longer are teams stuck waiting on slow, expensive human reviews or relying on rigid rule-based scripts that miss the nuance of real-world responses. Today, a well-configured judge model can evaluate thousands of outputs in minutes, flag hallucinations, score faithfulness, and even reason why a response fell short. This guide is your comprehensive roadmap to understanding, implementing, and trusting LLM-based evaluation systems in 2026 - from the ground up.
1. What Is LLM-as-a-Judge?
1.1 Definition of LLM-as-a-Judge
At its core, LLM as a Judge refers to using a large language model - typically a powerful, instruction-tuned one - to evaluate the output of another AI model. Think of it as hiring a senior editor to proofread the work of a junior writer, except both are AI. The judge model receives a prompt, the original AI's response, and optionally a reference answer or rubric. It then returns a score, a verdict, or a detailed critique. The concept sounds almost recursive, but it works surprisingly well when designed thoughtfully. The judge doesn't just mechanically check facts - it reasons, weighs context, and mirrors the kind of holistic judgment a human evaluator would apply.
1.2 Why AI Systems Need Automated Evaluation
Think about the scale at which modern AI applications operate. A customer support bot might handle 50,000 conversations a day. A RAG-based knowledge assistant might answer thousands of queries from employees every hour. Manually reviewing even, a fraction of those outputs would require entire departments of human annotators - and they'd inevitably miss things, get tired, or apply standards inconsistently. Automated LLM evaluation solves this problem by providing a scalable, consistent, and programmable layer of AI quality assurance that never sleeps, never gets fatigued, and can apply the same rubric to the millionth response as it did to the first.
1.3 How LLM-as-a-Judge Differs from Traditional Evaluation Methods
Traditional LLM benchmarking relied on fixed datasets and exact match scoring. If the model said 'Paris' and the right answer was 'Paris,' it passed. If it said 'The capital of France is Paris' - it might fail, even though it was correct. That brittleness is what LLM-based evaluation overcomes. Instead of rigid string matching, judge models understand context, paraphrase equivalence, and the spirit of an answer. They can evaluate open-ended, generative outputs that no rule-based system could reliably assess. The shift is from checking answers to understanding them.
2. Why LLM-as-a-Judge Has Become Essential in 2026
2.1 Rapid Growth of AI Applications
2026 is not 2022. AI is no longer a pilot project or an innovation lab experiment. It's embedded in hospitals, law firms, banks, e-commerce platforms, and government services. Every one of those deployments generates outputs that need to be reliable. The volume of AI-generated content has exploded to a point where human oversight alone is simply not operationally viable. This explosion has made AI evaluation frameworks not just a best practice - they're a business necessity.
2.2 Limitations of Human Evaluation
Human evaluators are gold standard in many ways - they bring genuine understanding, cultural sensitivity, and domain expertise. But they're also slow, expensive, inconsistent across annotators, and prone to bias and fatigue. Two evaluators reviewing the same response can give wildly different scores depending on their background, mood, or interpretation of the rubric. LLM-as-a-Judge doesn't replace human judgment; it standardises and scales it, reserving human review for the edge cases and high-stakes outputs that truly need it.
2.3 Need for Scalable AI Quality Assurance
AI quality assurance in 2026 looks nothing like software QA from a decade ago. You can't write test cases for every possible user's query. You can't anticipate every hallucination or off-topic drift. What you can do is deploy a continuous evaluation pipeline that monitors outputs in near real-time, flags anomalies, tracks metric trends, and alerts teams before small problems become PR disasters. That's precisely what well-built LLM evaluation systems deliver - a living, breathing quality gate that evolves alongside your model.
2.4 Enterprise Adoption of Automated Evaluation
Enterprises aren't just experimenting anymore; they're standardizing. Major tech companies, consulting firms, and regulated industries have begun treating LLM evaluation metrics as part of their model of governance and compliance frameworks. In regulated sectors like healthcare and finance, demonstrating that your AI outputs are continuously monitored and evaluated is quickly becoming a compliance expectation, not just a technical nicety.
3. How LLM-as-a-Judge Works
3.1 Step 1: User Query and Model Response
The process starts by capturing what actually happened in your application. A user submits a query, and the target model (the one being evaluated) generates a response. Both the query and the response are logged and passed downstream to the evaluation pipeline. This sounds simple, but getting this instrumentation right - capturing context, session state, retrieved documents, tool outputs - is foundational to everything that follows.
3.2 Step 2: Creating Evaluation Prompts
Next, the evaluation prompt is assembled. This is where real engineering happens. The prompt typically includes: the original user query, the model's response, any reference answer or ground truth, the retrieved context (in RAG scenarios), and a detailed rubric explaining what the judge should evaluate and how. The quality of this prompt directly determines the quality of your evaluation. Vague prompts produce vague judgments. Specific, well-structured prompts produce actionable insights.
3.3 Step 3: Scoring and Reasoning
The judge model then processes the evaluation prompt and generates both a score and a chain-of-thought explanation. The reasoning component is often more valuable than the score itself - it tells you not just that a response scored 3 out of 5, but why. Was the answer factually incorrect? Did it miss the user's intent? Was it technically accurate but unhelpfully verbose? This transparency is what makes LLM-based evaluation genuinely useful for improving models, not just measuring them.
3.4 Step 4: Generating Evaluation Metrics
Finally, scores and reasoning are aggregated into structured metrics. These might be stored in a database, surfaced in a monitoring dashboard, sent as alerts, or fed back into model training pipelines. The output isn't just a number - it's a dataset of diagnostic information that engineering and product teams can act on. Done well, this step closes the loop between evaluation and improvement.
4. Types of LLM-as-a-Judge Evaluation Methods
4.1 Pointwise Evaluation
Pointwise evaluation scores a single response in isolation, typically on a numerical scale (e.g., 1–5) or a categorical label (e.g., Pass/Fail). It's the simplest form and works well for high-volume, automated pipelines where you need fast, independent assessments. The downside is that scores can lack calibration - a 4/5 from one judge prompt might mean something different from another. It's best used when you have a well-defined rubric and consistent prompt design.
4.2 Pairwise Evaluation
Pairwise evaluation presents the judge with two responses to the same query and asks which is better. This mirrors how humans naturally make comparative judgments and tend to produce more reliable results than absolute scoring. It's particularly powerful during model comparison - A/B testing different model versions, prompts, or fine-tunes. The tradeoff is scale: comparing every pair across thousands of examples gets computationally expensive fast.
4.3 Listwise Evaluation
Listwise evaluation ranks multiple responses simultaneously. Instead of binary comparisons or isolated scores, the judge orders a set of responses from best to worst. This is valuable when you're evaluating retrieval systems, comparing multiple model candidates, or building preference datasets for RLHF. It's more cognitively demanding for the judge model, so prompt design matters even more here.
4.4 Rubric-Based Evaluation
Rubric-based evaluation provides the judge with a detailed, multi-dimensional scoring guide, think of it like an academic grading rubric. Each dimension (accuracy, completeness, tone, safety) gets its own criteria and weight. This is the most structured form of evaluation and produces the richest diagnostic data. It requires more upfront work to design the rubric, but it pays dividends in consistency, interpretability, and alignment with domain-specific requirements.
5. Key Evaluation Metrics Used in LLM-as-a-Judge
A robust AI evaluation framework doesn't rely on a single score. It measures across a spectrum of dimensions, each revealing a different facet of output quality. Here's what matters most:
5.1 Correctness
Does the response contain factually accurate information? Correctness is the bedrock metric; without it, everything else is polished noise. This is often evaluated against a ground truth or by the judge's own knowledge, and it's where hallucination detection plays a central role.
5.2 Relevance
Did the model actually answer what was asked? Relevance measures how well the response addresses the user's intent, not just the surface-level keywords. A technically accurate response that misses the user's actual question is still a failure.
5.3 Completeness
Was everything that needed to be said, said? Completeness catches responses that are technically correct but frustratingly partial - the kind that answer half the question and leave users searching for more.
5.4 Faithfulness Evaluation
Faithfulness evaluation is especially critical in RAG systems. It checks whether the model's claims are grounded in the retrieved source documents, rather than fabricated from prior knowledge. A model that confidently invents supporting evidence it wasn't given is a faithfulness failure - and in high-stakes domains, a serious liability.
5.5 Hallucination Detection
Hallucination detection is one of the most sought-after capabilities in any LLM evaluation metrics suite. It specifically identifies when the model states something as fact that isn't grounded in its context or training data. Modern judge models are increasingly good at catching these - but they still require thoughtful prompt design and domain-specific validation to be truly reliable.
5.6 Safety and Toxicity
Safety evaluation checks for harmful, toxic, biased, or policy-violating content. In consumer-facing applications, this is non-negotiable. Judge models can flag unsafe outputs faster and more consistently than human moderators, especially at scale.
6. LLM-as-a-Judge for RAG Evaluation
6.1 Why RAG Systems Need Specialized Evaluation
RAG evaluation is fundamentally different from evaluating a standalone language model. When you add a retrieval layer, you introduce a whole new category of failure modes. The retrieved chunks might be irrelevant. The model might ignore them and hallucinate anyway. Or the model might faithfully parrot incorrect information from a flawed document. Each of these requires a distinct evaluation lens and standard benchmarks don't capture them.
6.2 Context Relevance Evaluation
Context relevance asks: did the retrieval system surface documents that actually help answer the user's question? A high retrieval score with irrelevant chunks wastes tokens, confuses the model, and degrades output quality. Judge models can assess how well retrieved content maps to the user's intent - something keyword-based retrieval metrics completely miss.
6.3 Faithfulness Evaluation in RAG
In RAG contexts, faithfulness evaluation specifically checks whether each claim in the model's response can be traced back to the retrieved documents. If the model states something not found in the retrieved chunks, that is a faithfulness violation and potentially a serious error depending on the use case.
6.4 Hallucination Detection in RAG
RAG hallucinations are sneakier than general hallucinations. The model has real documents in front of it, so it feels more authoritative - but it may still extrapolate, blend information incorrectly, or confidently state things do not present in the context. Dedicated hallucination detection prompts that compare the response line-by-line against the retrieved context are the gold standard here.
7. LLM-as-a-Judge for AI Agent Evaluation
7.1 Challenges of Evaluating AI Agents
AI agent evaluation is arguably the hardest problem in the entire evaluation space right now. Unlike a single-turn Q&A, agents take sequences of actions, call tools, plan multi-step tasks, and operate over extended time horizons. Evaluating them requires tracking not just final outputs but intermediate reasoning, tool selection decisions, error recovery behaviors, and goal completion. Traditional metrics simply weren't built for this.
7.2 Evaluating Tool Usage
Did the agent use the right tool, with the right parameters, at the right time? Tool usage evaluation is one of the most practical and high-value AI agent evaluation metrics. A judge model can review the tool call log and assess whether each action was necessary, appropriate, and correctly executed - catching both over-use (calling tools when unnecessary) and under-use (missing opportunities to retrieve critical data).
7.3 Evaluating Planning and Reasoning
Reasoning quality is the hardest thing to evaluate, but also the most important thing. Judge models can assess whether the agent's chain-of-thought was logical, whether it correctly identified subgoals, and whether its plan was coherent given the available information. This requires sophisticated judge prompts - but when done well, it provides insight no other evaluation method can.
7.4 Task Completion Assessment
Ultimately, did the agent accomplish what it was asked to do? Task completion assessment is the bottom-line metric for agentic systems. It requires the judge to understand the original goal, trace the execution path, and make a holistic determination about success - including partial credit for tasks that were mostly completed.
8. Popular LLM-as-a-Judge Frameworks and Tools in 2026
The ecosystem of automated LLM evaluation tools has matured significantly. Here's a practical rundown of what's worth knowing:
8.1 DeepEval
DeepEval has become one of the most developer-friendly evaluation frameworks in the ecosystem. It supports a wide range of LLM evaluation metrics out of the box - hallucination, faithfulness, answer relevancy, contextual precision - and integrates cleanly into CI/CD pipelines. Its syntax is intuitive enough for quick adoption while being flexible enough for production-grade deployments.
8.2 Ragas
Ragas was purpose-built for RAG evaluation and remains the go-to tool for teams with retrieval-augmented architectures. Its core metrics - context relevance, faithfulness evaluation, answer relevance, and context recall - map directly to the failure modes that RAG systems encounter in production. If you're building on top of a vector database and retrieval pipeline, Ragas should be in your stack.
8.3 LangSmith
LangSmith offers the most polished observability experience for LangChain-based applications. Its evaluation suite is tightly integrated with tracing, making it easy to correlate evaluation outcomes with specific execution paths. For teams already in the LangChain ecosystem, it's often the default choice.
8.4 OpenAI Evals
OpenAI's open-source evaluation framework is highly flexible and supports custom evaluation graders alongside built-in metrics. It's particularly strong for model-level benchmarking and is widely used for LLM benchmarking across research and enterprise settings.
8.5 Braintrust
Braintrust focuses on continuous evaluation and dataset management. It shines in iterative development workflows where you're rapidly tuning prompts and need to track evaluation scores across experiments over time. Its UI makes it easy to spot regressions and understand what changed between runs.
8.6 Phoenix by Arize AI
Phoenix is Arize AI's open-source observability and evaluation tool. It's particularly well-suited for production monitoring use cases - tracking quality drift over time, surfacing problematic clusters of outputs, and integrating with existing ML observability infrastructure.
9. Building an LLM-as-a-Judge System
9.1 Define Evaluation Objectives
Before writing a single line of evaluation code, get crystal clear on what you're trying to measure and why. Are you monitoring a production system for quality drift? Comparing model versions before a deployment? Auditing for compliance? Each of these objectives demands a different evaluation design. Skipping this step leads to evaluation systems that generate numbers without generating insight.
9.2 Create Evaluation Rubrics
A good rubric is half the battle. For each dimension you want to evaluate, define clearly what a 1 looks like versus a 3 versus a 5. Include examples. Specify edge cases. The more concrete your rubric, the more consistent and trustworthy your judge's outputs will be. Vague criteria produce vague scores - and vague scores produce useless metrics.
9.3 Select a Judge Model
Not all models make good judges. You generally want a model that is more capable than the one being evaluated, has strong instruction-following, and produces structured, consistent outputs. GPT-4 class models and Claude Opus are popular choices. For specialized domains, fine-tuned judge models are emerging as a best practice - trained specifically to apply consistent evaluation criteria in areas like legal, medical, or financial AI.
9.4 Design Evaluation Prompts
Your evaluation prompt is your most important engineering artifact. It should include: clear task framing, the full context (query + response + source documents), the rubric with scoring criteria, and an instruction to provide reasoning before delivering a score. Request structured output - JSON works well - to make downstream parsing reliable. Test your prompts extensively before deploying them to production.
9.5 Validate Against Human Ratings
Before trusting your judge in production, validate it. Collect a representative sample of human-labeled examples across the quality spectrum - high, medium, and low quality responses - and measure how well your judge's scores correlate with human ratings. An inter-rater agreement score (Cohen's Kappa or Spearman's rank correlation) gives you a calibrated sense of how much to trust the automated system.
10. Benefits of Using LLM-as-a-Judge
10.1 Scalability
The most obvious benefit: you can evaluate millions of outputs without linearly scaling your team. What would take 50 human annotators six months to review can be processed in hours. This makes continuous, production-scale AI quality assurance not just feasible, but practical.
10.2 Faster Feedback Loops
When you can evaluate a prompt change in minutes rather than weeks, you move faster. Development teams get signal almost immediately. Product teams can test UX variations. Fine-tuning runs can be assessed before they reach production. Faster evaluation means faster iteration - and faster iteration means better models.
10.3 Cost Reduction
Human annotation is expensive, especially for specialized domains. Automated LLM evaluation typically costs a fraction of equivalent human review, even with frontier model API costs factored in. The savings compound as you scale, and they allow smaller teams to maintain evaluation rigor that previously required enterprise-level annotation budgets.
10.4 Better Model Benchmarking
LLM benchmarking with judge models captures dimensions of quality that static benchmarks completely miss. You're not just measuring whether the model gets the right answer on a fixed test set - you're measuring how well it serves real users, in real conditions, on real queries. That's a fundamentally more meaningful evaluation.
11. Challenges and Limitations of LLM-as-a-Judge
Let's be honest, LLM-as-a-Judge is not perfect. Understanding its failure modes is essential to using it responsibly.
11.1 Position Bias
In pairwise evaluations, judge models often favor whichever response appears first in the prompt. This positional preference has nothing to do with actual quality and can significantly skew your comparison results. The fix: randomize response order across evaluation runs and average the results.
11.2 Length Bias
Longer responses tend to score higher even when they're padded with filler. Judge models can mistake verbosity for thoroughness. Counter this with explicit rubric criteria that reward conciseness and penalize unnecessary length.
11.3 Self-Preference Bias
Models tend to prefer responses that resemble their own style. If you use GPT-4 as a judge and GPT-4 as the evaluated model, you may get artificially inflated scores. Use a diverse set of judge models - ideally from different model families - to mitigate this.
11.4 Hallucinated Evaluations
Ironically, judge models can themselves hallucinate. They might cite reasons for a low score that aren't actually present in the response, or confidently flag a factual error that doesn't exist. This is why validation against human ratings is so important - it catches systematic evaluation errors before they corrupt your metrics.
12. Best Practices for Reliable LLM-as-a-Judge Evaluations
12.1 Use Structured Rubrics
Every evaluation dimension should have a clear, anchored rubric with concrete examples of what each score level looks like. Ambiguous criteria lead to inconsistent scores. Inconsistent scores lead to metrics you can't trust.
12.2 Perform Human Validation
Never deploy an evaluation system without first validating it against human judgments. Measure correlation, identify systematic biases, and tune your prompts accordingly. Human validation isn't a one-time exercise - revisit it periodically as your application and user base evolve.
12.3 Use Multiple Judge Models
Diversify your judge models. Using two or three models from different families - and averaging or reconciling their scores - reduces individual model biases and produces more robust evaluations. When judges disagree significantly, that's itself a signal worth investigating.
12.4 Monitor Evaluation Drift
Judge model behavior can drift over time as underlying models are updated. A score of 4/5 in January might mean something different in September. Track your evaluation distributions over time and set up alerts for significant shifts that might indicate model or evaluation drift.
13. Real-World Use Cases of LLM-as-a-Judge
13.1 Customer Support Chatbots
Customer support is one of the highest-stakes and highest-volume AI applications. Judge models evaluate response accuracy, tone appropriateness, policy compliance, and resolution quality - at the scale of millions of daily conversations. Teams use evaluation insights to identify knowledge gaps, retrain models, and catch regressions after product changes.
13.2 Enterprise Knowledge Assistants
Internal knowledge assistants built on RAG architectures need rigorous faithfulness evaluation to ensure they're citing the right internal documents and not mixing up policies, procedures, or data across departments. AI evaluation frameworks are central to maintaining trust in these high-stakes internal tools.
13.3 Healthcare AI Applications
In healthcare, the cost of hallucination is potentially a patient's wellbeing. Medical AI systems use specialized judge models trained on clinical knowledge to evaluate accuracy, completeness, and safety of AI-generated responses. These evaluation systems often combine automated LLM evaluation with mandatory human review for any flagged outputs.
13.4 Financial AI Systems
Financial AI applications face strict regulatory requirements around accuracy and explainability. Judge models help compliance teams monitor AI outputs for regulatory violations, factual errors, and inappropriate financial advice - providing an audit trail that regulators increasingly expect.
14. The Future of LLM-as-a-Judge
14.1 Specialized Judge Models
The next wave of innovation is domain-specific judge models. Rather than applying a general-purpose LLM to evaluate medical or legal or financial outputs, organizations will fine-tune dedicated judge models on expert-labeled datasets within their domain. These specialized judges will have deeper calibration and lower hallucination rates within their areas of expertise.
14.2 Agentic Evaluation Systems
As AI agents become more prevalent, evaluation systems will themselves become more agentic, automatically designing test cases, running evaluations, diagnosing failure patterns, and triggering retraining pipelines without human intervention. The evaluation layer is evolving from a reporting tool into an autonomous quality management system.
14.3 Real-Time AI Monitoring
Real-time evaluation - where outputs are scored within milliseconds of generation - is moving from experimental to practical. This enables live guardrails that can intercept and modify problematic responses before they reach users, turning evaluation from a retrospective audit into a proactive quality gate.
14.4 Human-AI Hybrid Evaluation
The future isn't purely automated - it's intelligently hybrid. Automated LLM evaluation handles the volume, applies consistent criteria, and surfaces edge cases. Human evaluators focus their expertise on the cases that matter most: novel failure modes, high-stakes outputs, and calibration of the evaluation system itself. This hybrid model delivers the best of both worlds: scale and nuance.
Conclusion
LLM-as-a-Judge is no longer optional; it is the backbone of reliable AI quality assurance in 2026. From RAG evaluation to AI agent evaluation, it gives teams the scale, consistency, and speed that human review simply cannot match. Applied with proper rubrics, thorough human validation, and diverse judge models, it turns evaluation from a costly bottleneck into a real competitive advantage. The organizations winning with AI today are not just building better models, they are measuring them smarter. Build with clear intention, evaluate continuously, catch failures early, and ship AI your users can trust every time.
Related Blogs
Be the first to read our articles.